教師あり学習
大量のメールがあって、それぞれ人間の目でSPAMかどうかが判定済みであるとします。
それらのメールの何となくSPAMっぽい2単語「主人」「オオアリクイ」に注目し、各メールにそれらの単語が何回出てくるかを数えてグラフにプロットしたら下記のようになったとします。
(「主人」出現回数を 、「オオアリクイ」出現回数を
、「オオアリクイ」出現回数を とおきます。)
とおきます。)
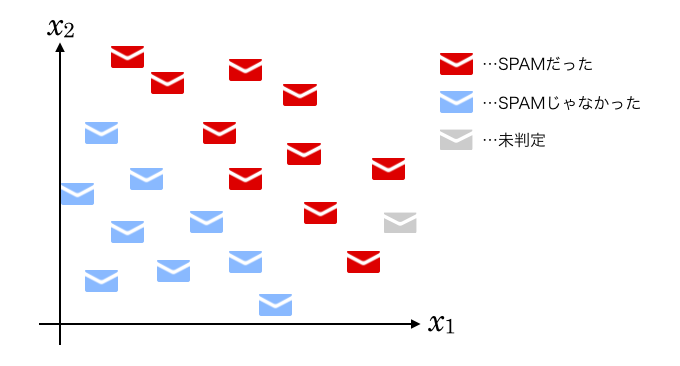
何だか、グラフ中に直線を引けばSPAMとそうでないメールを分けられそうだと思いませんか。
そしてその直線を基準にすれば、未判定のメールがSPAMなのかどうかも判断できそうな気がしませんか。
これが識別関数による教師あり学習の基本です。
教師あり学習では、教師データと呼ばれるデータをたくさん読み込ませて機械に学習させます。
教師データというのは「パラメータと正解ラベルの組」です。今回の例でいくとパラメータとは「主人」「オオアリクイ」という単語の数、正解ラベルとはSPAMかどうかのフラグ(事前に判明しているもの)を指します。
「この単語が○個、こっちの単語が△個あったらSPAMだよ」ということを教えてくれる教師というわけです。
識別関数
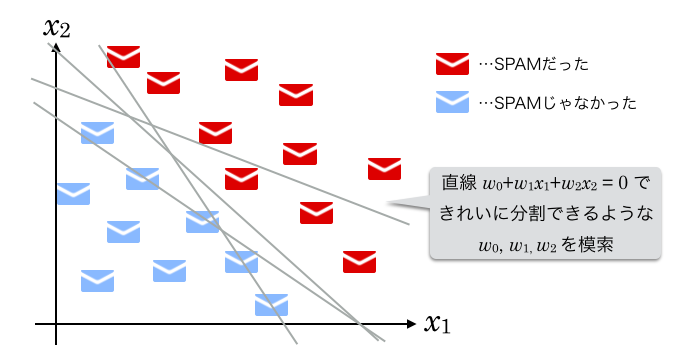
SPAMとそうでないメールを分ける直線の式を、3つの定数  を使って
を使って

とおきます。
移項して、中学で学ぶような「傾きと切片」の式に直すと

となりますね。
が何の値なのかはさておき、それら3つが決まれば直線の傾きや位置が決まるのがわかると思います。
この適切な を機械によって求める作業がここでの「学習」です。
(実際に求める方法は次回解説します。)
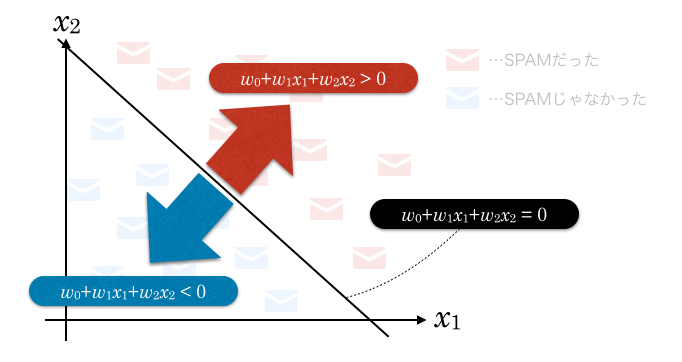
この直線で分割された片方のエリアでは

となり、もう一方のエリアでは

となります。
これは または について不等式を解いてみるとわかると思います。
の値を調整し(つまりグラフの直線を動かし)、教師データ中の全てのSPAMが のエリアに、全ての非SPAMが のエリアに入るようになれば学習完了です。
その後、  の と に、新しい(SPAMかどうかが不明な)メールに含まれる「主人」「オオアリクイ」の単語数を代入すると、その結果が0より大きいか小さいか(グラフで言えば、直線をはさんだどちらのエリアにプロットされるか)でSPAM識別ができるということになります。
の と に、新しい(SPAMかどうかが不明な)メールに含まれる「主人」「オオアリクイ」の単語数を代入すると、その結果が0より大きいか小さいか(グラフで言えば、直線をはさんだどちらのエリアにプロットされるか)でSPAM識別ができるということになります。
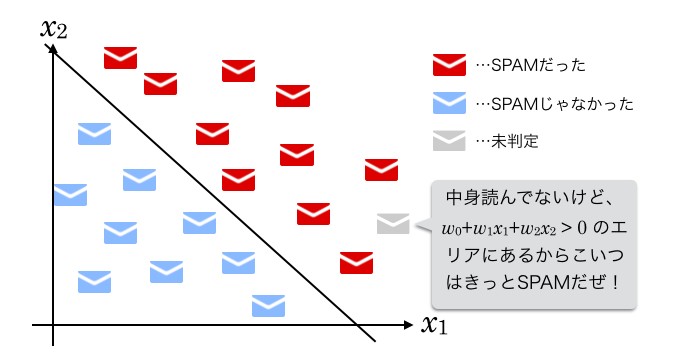
この がここでの識別関数です。
ベクトルで表現する
ここでベクトルの概念を導入します。1
一般に、ベクトル  とベクトル
とベクトル  の内積は、下記のように定義されます。
の内積は、下記のように定義されます。
![\[\bm{a} \cdot \bm{b} = a_1 b_1 + a_2 b_2 + \cdots + a_n b_n\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-aaf894fa5904786353503d0798c69e78_l3.svg "Rendered by QuickLaTeX.com")
なので、  ,
,  とおくと、
とおくと、 は、
は、
![\[\bm{w} \cdot \bm{x} = 0\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-cb20c60fa8ccbd0ce6de98760ac159dd_l3.svg "Rendered by QuickLaTeX.com")
というとてもシンプルな形で表現することができます。2
以降、内積の記号を省略してこれを
![\[\bm{w} \bm{x} = 0\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-bdc370b8ff877dc14fdae78c51037feb_l3.svg "Rendered by QuickLaTeX.com")
と記述することにします。
n次元の場合を考える
ここまでは、メール中の2単語に注目した場合を考えました。
2次元なのでグラフは平面上に描くことができ、それを分割するのは直線でした。
しかし実際にはたった2単語でSPAMかどうかを判定するのは難しいです。
3単語の場合はどうでしょう?
グラフで表すと、3次元なので立体空間になります。
立体空間を2つに分けるのは、線ではなく面になりますね。
この面が平面である場合、式はこのように表現できます。

 と
と  が増えましたが、これもベクトルで下記のように表現できます。3
が増えましたが、これもベクトルで下記のように表現できます。3

では4単語の場合はどうでしょう?
4次元になるとグラフで表現するのが非常に難しくなります。
しかし実はあまり難しく考えなくていいのです。
3次元までと同じように、 と
と  を増やした下記の式で分割することを考えます。
を増やした下記の式で分割することを考えます。

これもベクトルの次元数が変わるだけで、やはり下記のように表現できます。

3次元空間に生きる我々は、4次元以上のグラフをイメージすることができません。
しかしそれでいいのです。
2次元や3次元と同じように、上記のような数式で表すことさえできれば、計算はできます。
要は、数式に値を代入した結果が0より大きいか小さいかがわかればいいのです。
これは5次元でも1000000次元でも同じです。
線形分離可能とは
このように、n次元空間上にある点の集合を

で分割できることを、線形分離可能と言います。
再三になりますが、2次元空間を分割するのは直線です。3次元空間だと平面。
4次元以上だと空間そのものがイメージできないのですが、その空間も同じように  で表される「何か」で分割できると考えることができます。
で表される「何か」で分割できると考えることができます。
2次元空間における直線、3次元空間における平面、4次元以上の空間のその「何か」をまとめて、超平面と呼びます。
線形分離可能とは、n次元空間上の点の集合を超平面で分割できること、ということができます。
2次元の場合と同じく、分割された片方のエリアは  となり、もう一方は
となり、もう一方は  となります。
となります。
線形分離不可能な問題もあります。
例えば2次元の場合、グラフにプロットした結果、境界線が曲がっていたり、点が混ざっていたりすると直線で分割できませんね。
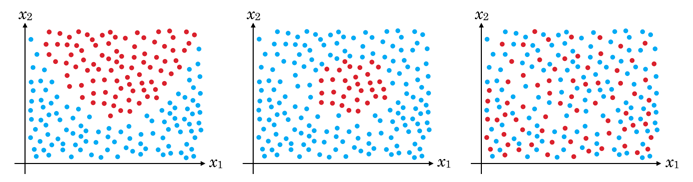
この問題を解決する手法の1つは次の次くらいの回で説明します。
まずは、線形分離可能な問題から考えましょう。
思いのほか長くなった
次回は、実際に  の値を求めていく方法を書きます。
の値を求めていく方法を書きます。
キーワードは単純パーセプトロンと勾配降下法です。
-
ベクトルを
 のような矢印をつけた記号で表す方法がありますが、この記事では太字で
のような矢印をつけた記号で表す方法がありますが、この記事では太字で  のように表現します。以降もその手法を踏襲しますが、時々太字にするのを忘れるかも知れません…その場合はご容赦ください。 ↩
のように表現します。以降もその手法を踏襲しますが、時々太字にするのを忘れるかも知れません…その場合はご容赦ください。 ↩
-
 としている資料も多いです。その表現は
としている資料も多いです。その表現は  とし、
とし、  の代わりに
の代わりに  を使っているだけで、意味するところは同じです。そちらの方がわかりやすい人もいるかも知れませんね。
を使っているだけで、意味するところは同じです。そちらの方がわかりやすい人もいるかも知れませんね。

また、 の部分を
の部分を  のように記載している資料もあります。これは、
のように記載している資料もあります。これは、  および
および  を単に値の集まりとしてのベクトルではなく列ベクトルとして扱っている(つまり行列の積として記述している)だけで、やはり意味するところは同じです。 の右上に
を単に値の集まりとしてのベクトルではなく列ベクトルとして扱っている(つまり行列の積として記述している)だけで、やはり意味するところは同じです。 の右上に  がありますが、これは「の乗」ではなく、「の転置行列」を表します。
がありますが、これは「の乗」ではなく、「の転置行列」を表します。
 ↩
↩
-
「
 」は「ただし」とでも読み替えてください。 ↩
」は「ただし」とでも読み替えてください。 ↩