XOR問題:単純パーセプトロンの限界
単純パーセプトロンの学習によって論理演算(ANDやORなど)の役割を果たす識別器を作ることを考えます。
真 = 1, 偽 = 0 とおき、 ,
,  それぞれでいずれかを入力します。
それぞれでいずれかを入力します。
パーセプトロンを通過した結果、それらを論理演算した値(0または1)が出力されるようにします。
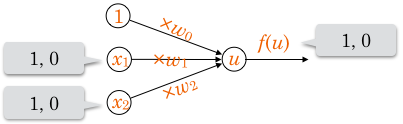
0か1の出力なので、活性化関数  として単位ステップ関数を利用します。
として単位ステップ関数を利用します。
![\[f(u) = \begin{cases} 1 & (u \geq 0) \\ 0 & (u < 0) \end{cases}\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-c8801a98889d1c8b4fbee9168e3d4d05_l3.svg "Rendered by QuickLaTeX.com")
単純パーセプトロンにおける重みベクトルの学習手順は前回説明したとおりですので、以下、学習によって具体的にどのような重みになってほしいか?という観点で話を進めます。
以下のようなアプローチで考察ができるのは2次元(入力が2つ)ならではです。
OR(論理和)
まず、ORの役割を果たす単純パーセプトロンについて考えます。
OR の定義は下表のような感じですよね。
|
|
OR |
|---|---|---|
| 1 | 1 | 1 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 0 | 0 |
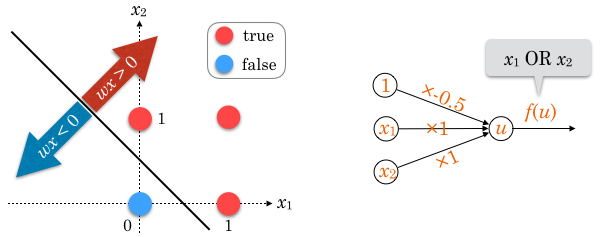
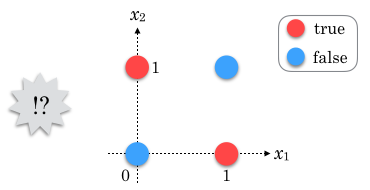
入力値  をグラフにプロットし、出力値の境界に適当な直線を引いてみると、例えば傾きが-1で切片が0.5、つまり
をグラフにプロットし、出力値の境界に適当な直線を引いてみると、例えば傾きが-1で切片が0.5、つまり  の直線で分割できることがわかります(下図参照)。1
の直線で分割できることがわかります(下図参照)。1
移項して  の形に直すと、
の形に直すと、  です。
です。
左辺の , に図中の赤い点の値を代入すると  、青い点の値を代入すると
、青い点の値を代入すると  となり、この
となり、この  が識別関数として機能していることがわかります。
が識別関数として機能していることがわかります。
つまり、学習の結果 重みベクトルが例えば  になれば、この単純パーセプトロンは OR の役割を果たします。
になれば、この単純パーセプトロンは OR の役割を果たします。
なお、  :
:  :
:  の比率がだいたいそれに近ければ同じ出力をしたりします。
の比率がだいたいそれに近ければ同じ出力をしたりします。
AND(論理積)
AND は下表です。
|
|
AND |
|---|---|---|
| 1 | 1 | 1 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 0 |
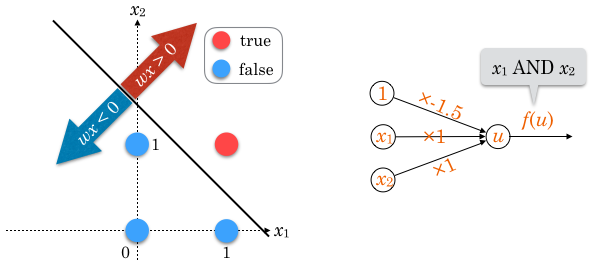
入力値 をグラフにプロットし、出力値の境界に直線を引いてみると、例えば  で分割でき、これを OR と同じように整理すると
で分割でき、これを OR と同じように整理すると  です。
です。
NAND(否定論理積)
NAND(つまり NOT AND)は下表です。
|
|
NAND |
|---|---|---|
| 1 | 1 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 0 | 1 |
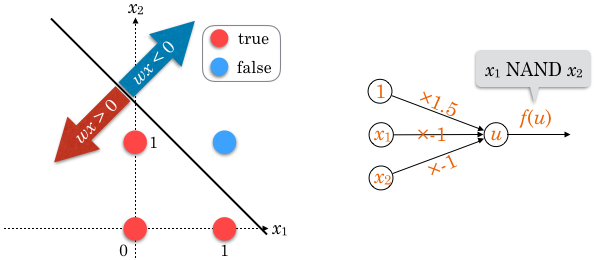
当然ですが、演算結果がANDと反転しています。
AND と同じ直線で分離できるのですが、直線で分離された両エリアの不等号が逆になります。
不等式の不等号を逆にするためには、両辺に -1 をかければいいですね。
よって、AND の重みの正負を逆転させた  が適切な重みの一例です。
が適切な重みの一例です。
XOR(排他的論理和)
XORは下表です。
|
|
XOR |
|---|---|---|
| 1 | 1 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 0 | 0 |
これまでとちょっと様子が違います。
グラフを見るとわかるように、4点を直線で分割することができません。
つまりこれは線形識別不可能な問題であり、単純パーセプトロンでは解決することができないのです。
多層パーセプトロン
XOR は、「, どちらかは真だが、『両方が真』ではない」時に真となります。
つまりこのように表現できます。

OR、AND、NAND を使って表現できました。
この3つの演算子は単純パーセプトロンで作成できるので、それらをつなぎ合わせることで結果的に XOR の役割を果たす識別器が作れます。
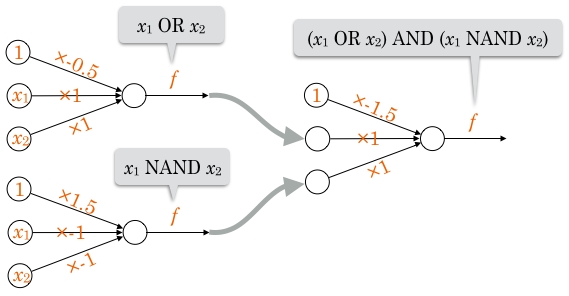
まとめた絵にするとこうです。
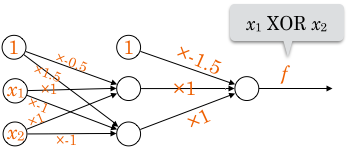
「あるユニットの出力を別のユニットの入力として使う」という構造を作ったことで、線形識別不可能な問題を解くことができました。2
これが多層パーセプトロンです。3
この例では、真ん中の2ユニットの出力が右のユニットの入力として使われています。
一般に、つなぎ合わせるユニットの数は問題によって様々ですが、非常に多くのユニットを結合させて利用することも多いです。
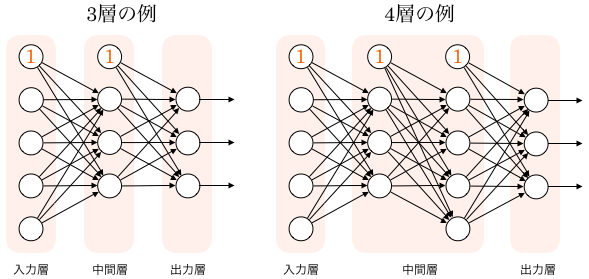
このように、ユニットが層状になっていることから多層パーセプトロンと言います。
上図で、一番左の層を入力層、一番右の層を出力層、それ以外の層を中間層または隠れ層と呼びます。
この図では出力層にユニットが複数ありますね。その意義の一例は後の項で述べます。
XORの例は、「多層にすることによって、【重みの値を適切に学習できさえすれば】線形識別不可能な問題も解くことができる」ことを示すために挙げました。
ただ、多層パーセプトロンの学習において、通常は単純パーセプトロンと同じ手順で重みを求めることはできません。
XOR問題は非常に単純な問題なので「中間層のユニットがどのような値を出力してほしいか?」や「各重みがどういった値になってほしいか?」が明らかでしたが、一般にそういったことはほぼあり得ないからです。(教師データが与えるのは「入力層に入力するパラメータ」と「出力層から出力される値に対応する正解ラベル」のみです。中間層ユニットの各出力に対応する正解ラベルはありません。)
というわけで、実際に重みを求める方法は次回解説します。
多クラス分類
ここまでの単純パーセプトロンの例では、SPAM識別や論理演算を扱いました。
これらはパラメータ(グラフの各点)を2つに分類する行為(SPAM/非SPAM、真/偽 など)なので、2クラス分類や二値分類などと呼びます。
これに対し、3つ以上に分類することを多クラス分類と呼んで区別したりします。
前回学んだ単純パーセプトロンで多クラス分類を行うには、分類すべきクラス数と同じ数だけ単純パーセプトロンを準備し、各入力に対してそのうち1つだけが発火(1を出力)するよう学習すればよいです。
入力に対し、単純パーセプトロンAは「クラスAに属するか否か」を判定、単純パーセプトロンBは「クラスBに属するか否か」を判定…という具合です。
4次元の入力をもとに3クラスに分類する例を図示するとこうなります。

ユニットの出力が別のユニットの入力になっていないという意味で、上記は多層パーセプトロンとは言えないことに注意してください(そのことがわかりやすいよう、上図では単純パーセプトロンの1つに色づけをしてあります)。
単純パーセプトロンが複数あるだけなので、各クラスに属するか否かがそれぞれ線形識別可能な問題でなければ学習できません。
一方、多層パーセプトロンで多クラス分類を行えば、線形識別不可能であっても分類できることがあります。
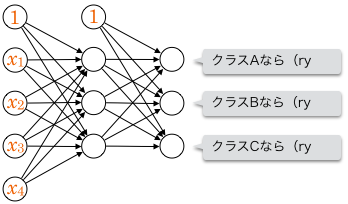
正解ラベルは、ベクトルを使って  のように表現することができます。
のように表現することができます。
この場合は出力層の1つめのユニットだけが1を出力すれば正解という意味です。
このようにして、例えばメール中の各単語の数をもとに自動でメールをカテゴリ分類する仕組みなどが作れます。
カテゴリ分けではなくタグ付けにするのであれば、出力層の複数ユニットが同時に1を出力することを許容してもいいですね。
多層パーセプトロンによってどのような問題が解けるかを考えると楽しいと思います。
次回は、実際に多層パーセプトロンでどのように重みを更新していくのか、その手順を書きます。