今回書くこと
前回、多層パーセプトロンの重み更新の理論として、誤差逆伝播法の考え方の概要を、数式を使って説明しました。
しかし出てきた数式が出力層付近のみの式だったので、今回はすべての層に一般化した更新式を導きます。
デルタの定義
ここで、今回とても重要になる定義をします。
任意の第 層
層  番目のユニットの重み付き和を
番目のユニットの重み付き和を  のように書くと定義しましたが、この で誤差関数
のように書くと定義しましたが、この で誤差関数  を偏微分したものを
を偏微分したものを  とおきます。
とおきます。
![\[\delta_k^{(l)} = \frac{\partial E}{\partial u_{k}^{(l)}}\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-767ed815cf38cafffc71cd92c43a009e_l3.svg "Rendered by QuickLaTeX.com")
上記はすべての出力ユニット1でそれぞれ定義されることにご注意ください。
例:  、
、 
なお、この値の意味は…と深く考える必要はありません。
後の計算式がわかりやすくなるように定義したものです。
 はギリシャ文字の
はギリシャ文字の  (デルタ)の小文字です。
(デルタ)の小文字です。
以下、これらの値をそのまま「デルタ」と呼ぶことにします。2
デルタを使って出力層の更新式を表す
出力層にひもづく重みの更新式は前回導きましたが、これをデルタを使った式で改めて導き直してみます。
まず出力層(第 層)
層) 番目のユニット出力値の式は下記ですね。
番目のユニット出力値の式は下記ですね。
![\[o_i^{(L)} = f(u_i^{(L)})\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-cbd770278bc8dea9281b9d2e63dd22f0_l3.svg "Rendered by QuickLaTeX.com")
![\[u_i^{(L)} = w_{i, 0}^{(L)} + w_{i, 1}^{(L)} o_1^{(L-1)} + w_{i, 2}^{(L)} o_2^{(L-1)} + \cdots\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-6e6f6a3c4f3382db03418679c311edd9_l3.svg "Rendered by QuickLaTeX.com")
勾配降下法による重み更新式はこうでした。(第層 番目ユニットの  番目の重み)
番目の重み)
![\[w_{i, j}^{(L)} \gets w_{i, j}^{(L)} - \rho \frac{\partial E}{\partial w_{i, j}^{(L)}}\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-a501185260b3e14bac5b16ba3cec47eb_l3.svg "Rendered by QuickLaTeX.com")
上記の  について
について
![\[\begin{align*} \frac{\partial E}{\partial w_{i, j}^{(L)}} & = \frac{\partial E}{\partial u_i^{(L)}} \frac{\partial u_i^{(L)}}{\partial w_{i, j}^{(L)}} \\ & = \delta_i^{(L)} o_j^{(L-1)} \end{align*}\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-030d28109ebe47fd3231047e3d16187c_l3.svg "Rendered by QuickLaTeX.com")
となります。
よって出力層の重みの更新式は
![\[w_{i, j}^{(L)} \gets w_{i, j}^{(L)} - \rho \delta_i^{(L)} o_j^{(L-1)}\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-edfa291080d1ae2f5a577ad54fd43540_l3.svg "Rendered by QuickLaTeX.com")
と表せます。
随分シンプルな式になりました。
ところで、出力層のデルタはどんな式で表せるでしょうか。展開してみます。
![\[\begin{align*} \delta_i^{(L)} & = \frac{\partial E}{\partial u_i^{(L)}} \\ & = \frac{\partial E}{\partial o_i^{(L)}} \frac{\partial o_i^{(L)}}{\partial u_i^{(L)}} \\ & = \left( o_i^{(L)} - t_i \right) f'(u_i^{(L)}) \end{align*}\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-29d6caf29a24ecdf1f608a7bcad7dae6_l3.svg "Rendered by QuickLaTeX.com")
項ごとの変形は前回やったことと同じですので、意味がわからない場合は前回の記事を参照してみてください。
デルタを使って出力層以外の更新式を表す
出力層以外の任意の第層について考えてみます。
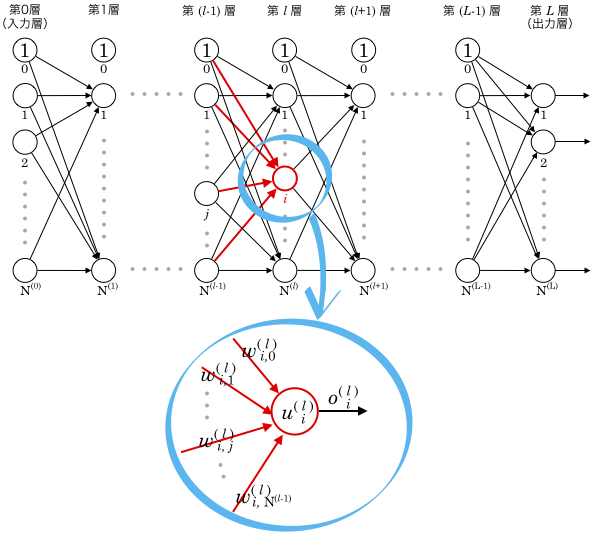
第層の番目のユニットの式は下記のようになります。
![\[o_i^{(l)} = f(u_i^{(l)})\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-b002457f9f4bcc8baa57764291e0f077_l3.svg "Rendered by QuickLaTeX.com")
![\[u_i^{(l)} = w_{i, 0}^{(l)} + w_{i, 1}^{(l)} o_1^{(l-1)} + w_{i, 2}^{(l)} o_2^{(l-1)} + \cdots\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-af29533656093e85975a09b42f6a311c_l3.svg "Rendered by QuickLaTeX.com")
勾配降下法による重み更新式はこうですね。(第層 番目ユニットの 番目の重み)
![\[w_{i, j}^{(l)} \gets w_{i, j}^{(l)} - \rho \frac{\partial E}{\partial w_{i, j}^{(l)}}\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-8a8c9874466e70c29fd7e65f3ad5c383_l3.svg "Rendered by QuickLaTeX.com")
上記の  は
は
![\[\begin{align*} \frac{\partial E}{\partial w_{i, j}^{(l)}} & = \frac{\partial E}{\partial u_i^{(l)}} \frac{\partial u_i^{(l)}}{\partial w_{i, j}^{(l)}} \\ & = \delta_i^{(l)} o_j^{(l-1)} \end{align*}\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-abd97ac8e7656bc3ddaa52183084fa0d_l3.svg "Rendered by QuickLaTeX.com")
と変形できるので、更新式は下記のようになります。
![\[w_{i, j}^{(l)} \gets w_{i, j}^{(l)} - \rho \delta_i^{(l)} o_j^{(l-1)}\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-cae82d016c022d29999dd53ba718374a_l3.svg "Rendered by QuickLaTeX.com")
出力層の場合とほとんど同じ式になっていることがわかるでしょうか?
ただし、デルタを展開すると、出力層とはだいぶ違う式になります。
展開してみましょう。下記の部分までは同じです。
![\[\begin{align*} \delta_i^{(l)} & = \frac{\partial E}{\partial u_i^{(l)}} \\ & = \frac{\partial E}{\partial o_i^{(l)}} \frac{\partial o_i^{(l)}}{\partial u_i^{(l)}} \end{align*}\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-62e20eccf53c54dddf1e52b9b0892003_l3.svg "Rendered by QuickLaTeX.com")
上式の最終行 第1項は、下記のように展開できます。
(前回名付けた、偏微分の公式の「難しい方」を使っています。)
![\[\begin{align*} \frac{\partial E}{\partial o_i^{(l)}} & = \sum_k \frac{\partial E}{\partial u_k^{(l+1)}} \frac{\partial u_k^{(l+1)}}{\partial o_i^{(l)}} \\ & = \sum_k \delta_k^{(l+1)} w_{k,i}^{(l+1)} \end{align*}\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-657aa23a7c3888f4d5e4b2b585b02f4b_l3.svg "Rendered by QuickLaTeX.com")
式中に第 層のデルタが出現しました。
層のデルタが出現しました。
前出のデルタ展開式に上記を当てはめます。
![\[\begin{align*} \delta_i^{(l)} & = \frac{\partial E}{\partial o_i^{(l)}} \frac{\partial o_i^{(l)}}{\partial u_i^{(l)}} \\ & = \sum_k \delta_k^{(l+1)} w_{k,i}^{(l+1)} f'(u_i^{(l)}) \end{align*}\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-58455f436cef37c0fb871ffbe43aa25f_l3.svg "Rendered by QuickLaTeX.com")
第層のデルタを表現するのに、第層のデルタを使うことができました。
これは、下記のことを表しています。
- 上の層の更新式を計算すると、その計算結果の一部を下の層の更新式に使い回すことができる
- ただし、この式は出力層では使えない
1つ目については、前回も触れた内容ですね。
2つ目については、層番号は出力層のが最大で、第 層というのはないからです。
層というのはないからです。
つまりデルタの式は、出力層( )とそれ以外(
)とそれ以外( )で違うということです。
)で違うということです。
出力層のデルタは、この記事の前半で式展開しましたね。
まとめます。
多層パーセプトロンの重み更新アルゴリズム
多層パーセプトロンの第層 番目ユニットの 番目の重みの更新式は下記で表せます。
ただし、
![\[\delta_i^{(l)} = \begin{cases} \left( o_i^{(l)} - t_i \right) f'(u_i^{(l)}) & (l = L) \\ \sum_k \delta_k^{(l+1)} w_{k,i}^{(l+1)} f'(u_i^{(l)}) & (l < L) \end{cases}\]](http://hokuts.com/wp-content/ql-cache/quicklatex.com-506bfd6c5c97c0467da0e9a4c5f1d3ec_l3.svg "Rendered by QuickLaTeX.com")
更新の手順は下記です。
- 多層パーセプトロン内のすべての重みをランダムに初期化
- 学習が完了するまで下記を繰り返す
- 多層パーセプトロンにパラメータを入力し、出力誤差を計算
- 上記更新式に従い、出力層から順にすべての重みの更新量を計算
- 計算した更新量をすべての重みに適用
既に述べましたが、この手法は 誤差逆伝播法 または バックプロパゲーション と呼ばれます。
これで多層パーセプトロンの実装ができます。
次回
次回は、ディープラーニングと画像識別の入り口をちょっとだけ紹介します。
 を出力しているユニット(バイアスの重みに繋がるユニット)は除きます。
を出力しているユニット(バイアスの重みに繋がるユニット)は除きます。